Kubernetes 使用 Kubeadm 搭建测试环境
部署的目标
一般生产环境都是多主多从,但是搭建起来很麻烦,所以这里主要描述的是一主两从的集群搭建方式。
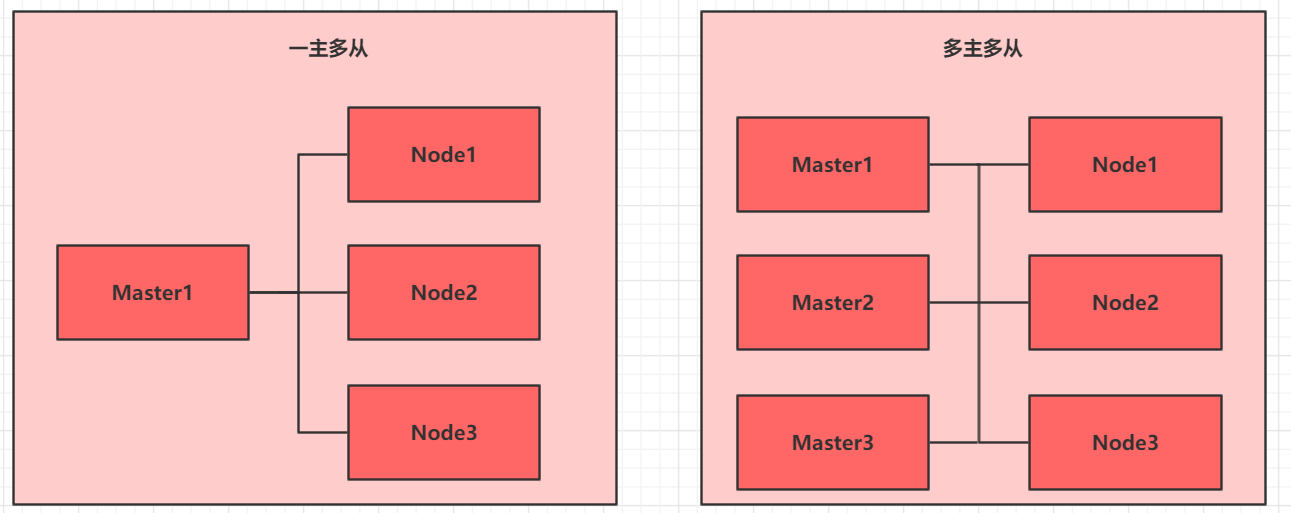
目前生产部署 Kubernetes 集群主要有三种方式:
1、minikube:一个用于快速搭建单节点 Kubernetes 的工具,minikube 可以借助于本地的虚拟化能力,通过 Hyperkit、Hyper-V、KVM、Parallels、Podman、VirtualBox 和 VMWare 等创建出虚拟机,然后在虚拟机中搭建出 Kubernetes 集群来。
minikube start --driver=docker \
--imageRepository=registry.cn-hangzhou.aliyuncs.com/google_containers \
--imageMirrorCountry=cn
但是这个 minikube 主要是用于快速搭建本地的开发测试环境,没办法用来搭建生产集群。
2、Kubeadm:用于快速搭建 Kubernetes 集群的工具,Kubeadm 是社区官方持续维护的集群搭建工具,在 Kubernetes v1.13 版本的时候就已经 GA 了(GA 即 General Availability,指官方开始推荐广泛使用),它跟着 Kubernetes 的版本一起发布,目前 Kubeadm 代码放在 Kubernetes 的主代码库中。这里主要也是讲如何使用 Kubeadm 去搭建。
3、二进制包:从官网下载每个组件的二进制包,依次部署每个组件,组成 Kubernetes 集群。(具体哪些组件可以参考 《Kubernetes 是什么》 这篇笔记的 “Kubernetes 的两类节点” 这节)
kubeadm 部署方式介绍
kubeadm 是官方社区推出的一个用于快速部署 kubernetes 集群的工具,这个工具能通过两条指令完成一个kubernetes 集群的部署:
- 创建一个 Master 节点 kubeadm init
- 将 Node 节点加入到当前集群中
# 将 Node 节点加入到当前集群中
$ kubeadm join <Master 节点的IP 和端口>
这里使用 VMWare 去搭建环境,这里分配 IP 地址:
| 角色 | IP地址 | 组件 |
|---|---|---|
| master01 | 192.168.150.100 | docker,kubectl,kubeadm,kubelet |
| node01 | 192.168.150.101 | docker,kubectl,kubeadm,kubelet |
| node02 | 192.168.150.102 | docker,kubectl,kubeadm,kubelet |
配置网络
首先确定物理机的网段:
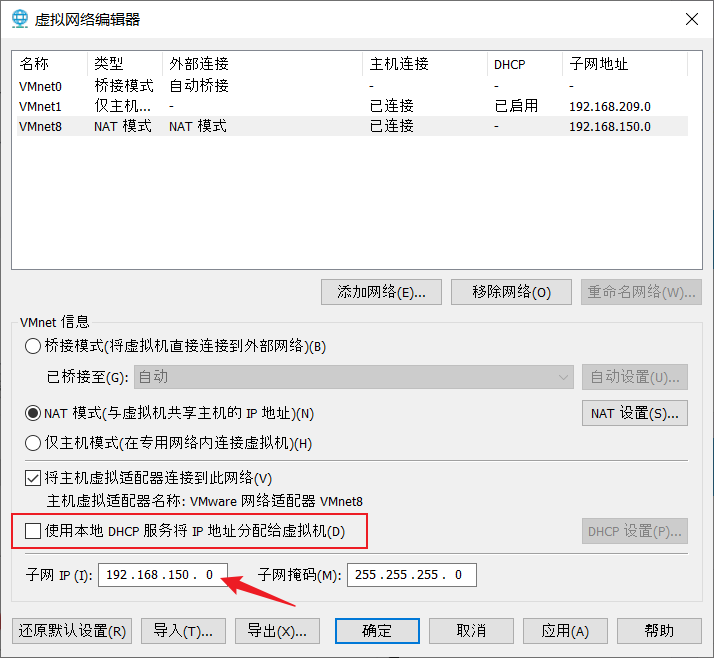
把 "使用本地DHCP服务将 IP地址分配给虚拟机" 前面的勾去掉,目的是禁止动态给ubuntu虚拟机分配IP地址,其它地方不用修改。
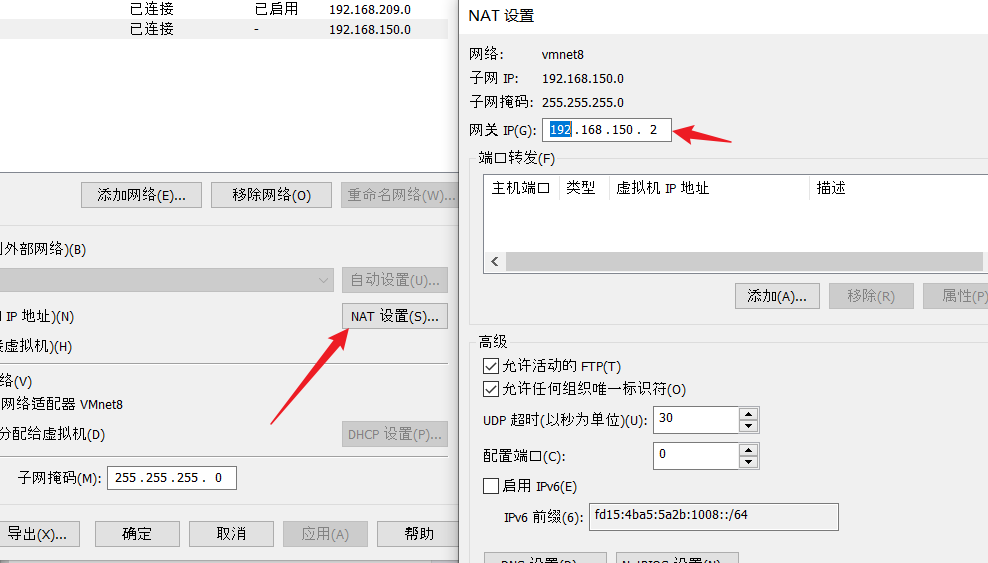
然后记录下 VMware 的网关IP地址
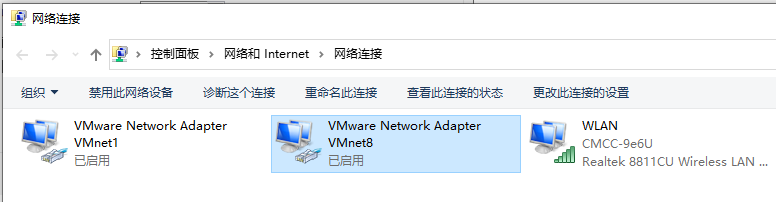
依次进入 控制面板 >> 网络和 Internet >> 更改适配器设置,右键 VMware Network Adapter VMnet8
在 VMware Network Adapter VMnet8 图标上右键,选属性,然后选择 “Internet协议版本4(TCP/Ipv4)” 选项,然后点击 "属性"按钮。
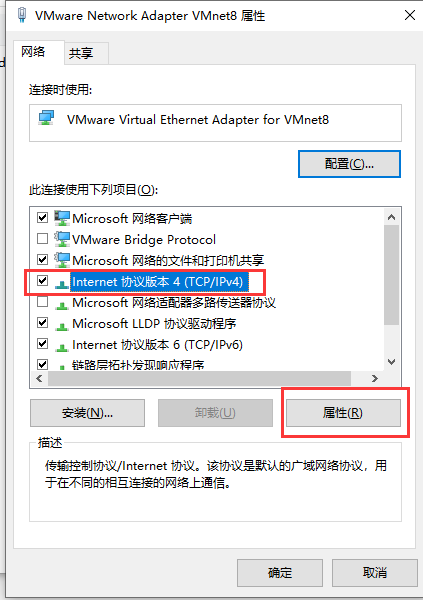
然后弹出属性框,可以看到 “使用下面的IP地址” 下的IP地址中的内容,为了不跟 Ubuntu 虚拟机配置的网关 ip 产生冲突,需要将这个 IP 地址改成别的 IP 地址,比如改成 192.168.150.3
然后其它地方不用更改,此步骤完成。
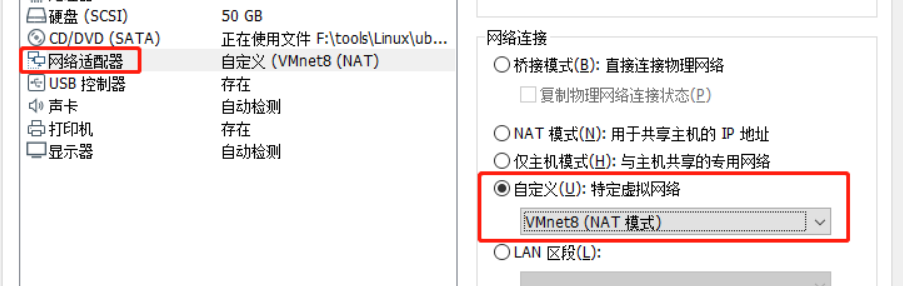
打开VMware,在【我的计算机】 下选中要配置的 Ubuntu 虚拟机,点击【编辑虚拟机设置】,在左侧的【硬件】栏中选中【网络适配器】,选中右侧【网络连接】中的【 自定义(U):特定虚拟网络 】选项,选中下面的 【VMnet8 (NAT模式)"】选项,点击【确定】按钮。

用 ip addr 命令查看网卡名称,下图可以看出,网卡名称是 ens33,网卡名称以自己的 Ubuntu 系统为准,你的网卡名称可能不是 ens33,有可能是 ens37 这种名称。
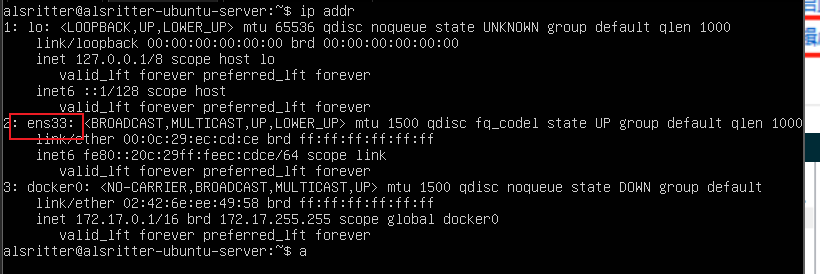
ip addr
修改网络配置文件,网络配置文件存放在 /etc/netplan 目录下
用 ls 命令查看配置文件
ls /etc/netplan

从图上可以看出网络配置文件名为:00-installer-config.yaml
sudo vim /etc/netplan/00-installer-config.yaml
编辑 00-installer-config.yaml 文件的内容为:
network:
version: 2
renderer: networkd
ethernets:
ens33: #网卡名,以ubuntu操作系统的网卡名称为准
dhcp4: no #ipv4关闭dhcp,用static模式
dhcp6: no #ip6关闭dhcp
addresses:
- 192.168.150.100/24 #本机IP地址
gateway4: 192.168.150.2 #vmware网关的的IP地址
nameservers: #DNS服务器
addresses: [114.114.114.114, 8.8.8.8, 1.1.1.1]
然后执行 sudo netplan apply 命令编译网络配置,
最后 ifconfig 检查:
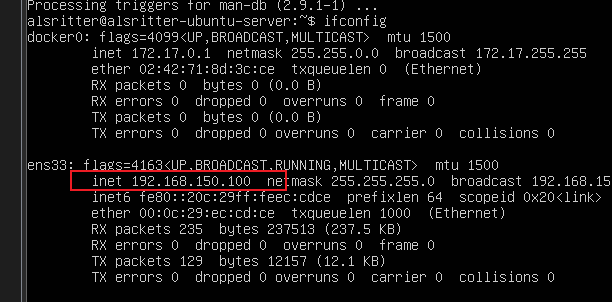
剩下的两个 Node 节点直接 Copy 就行了
NAT 模式物理机 ping 不通虚拟机
配置主机的 Host
为了方便集群的调用,这里配置一下主机名的解析
| 主机名 | IP地址 |
|---|---|
| master | 192.168.150.100 |
| node1 | 192.168.150.101 |
| node2 | 192.168.150.102 |
# 编辑 /etc/hosts 文件
192.168.150.100 master
192.168.150.101 node1
192.168.150.102 node2
然后可以关闭防火墙,以免对测试造成了影响
# 检查防火墙状态
sudo ufw status
# 启用防火墙
sudo ufw enable
sudo ufw default deny
# 关闭防火墙
sudo ufw disable
禁用 swap 分区
首先禁用 swap 分区,因为 Kubernetes 要求每个节点都禁用虚拟内存
1、不重启电脑,禁用启用 swap,立刻生效
# 禁用命令
sudo swapoff -a
# 启用命令
sudo swapon -a
# 查看交换分区的状态
sudo free -m

2、重新启动电脑,永久禁用 Swap
# 修改 /etc/fstab 文件
# 在swap分区这行前加 # 禁用掉
sudo vim /etc/fstab
如下所示:

配置 kube-proxy
为什么需要代理
容器的特点是快速创建、快速销毁,Kubernetes Pod 和容器一样只具有临时的生命周期,一个 Pod 随时有可能被终止或者漂移,随着集群的状态变化而变化,一旦 Pod 变化,则该 Pod 提供的服务也就无法访问,如果直接访问 Pod 则无法实现服务的连续性和高可用性,因此显然不能使用 Pod 地址作为服务暴露端口。
解决这个问题的办法和传统数据中心解决无状态服务高可用的思路完全一样,通过负载均衡和 VIP 实现后端真实服务的自动转发、故障转移。
这个负载均衡在 Kubernetes 中称为 Service,VIP 即 Service ClusterIP,因此可以认为 Kubernetes 的 Service 就是一个四层负载均衡
kube-proxy 默认会优先选择基于内核态的负载作为后端实现机制,目前 kube-proxy 默认是通过 iptables 实现负载的
流量传递到 iptables 的链
iptables 是 Linux 防火墙系统的重要组成部分,iptables 的主要功能是实现对网络数据包进出设备及转发的控制。当数据包需要进入设备、从设备中流出或者由该设备转发、路由时,都可以使用 iptables 进行控制。
修改 Linux 的内核参数,添加网桥过滤和地址转发功能,添加以下配置
在每个节点上将桥接的 IPv4 流量传递到 iptables 的链:
cat > /etc/sysctl.d/k8s.conf << EOF
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
vm.swappiness = 0
EOF
# 重新加载配置
sysctl -p
加载 br_netfilter 模块
# 加载网桥过滤模块
modprobe br_netfilter
# 查看网桥过滤模块是否加载
lsmod | grep br_netfilter
Linux 的 modprobe 命令用于从 Linux kernel 中装载和卸载模块。
Linux kernel 有一个模块化设计。一个 kernel 模块,通常被称为 驱动程序,是用来扩展内核功能的一段代码。模块要么被编译成可加载的模块,要么被打包进内核中。可加载的模块可以在内核运行时,按照需求加载或者卸载,而不需要重启系统。
启动上面加载的模块
# 生效
sudo sysctl --system
使用 ipvs 模块代理
在 kubernetes 中 service 有两种代理模型,一种是基于 iptables,另一种是基于 ipvs 的。ipvs的性能要高于 iptables 的,但是如果要使用它,需要手动载入 ipvs 模块。
LVS 是 Linux Virtual Server 的简称,也就是 Linux 虚拟服务器,LVS 是一种叫基于 TCP/IP 的负载均衡技术,转发效率极高,具有处理百万计并发连接请求的能力。
在每个节点安装 ipset 和 ipvsadm:
sudo apt install -y ipset ipvsadm
将需要启用的模块名写入 /etc/modules 系统启动时会自动加载
在所有节点执行如下脚本:
- Ubuntu
- Redhat
sudo sh -c "ls /lib/modules/$(uname -r)/kernel/net/netfilter/ipvs | grep -o \"^[^.]*\" >> /etc/modules"
sudo vim /etc/modules
# 再加上 nf_conntrack
# 加载模块
sudo depmod
sudo reboot
# 使用 modprobe 命令可以用于添加或者移除 Linux 内核模块
cat > /etc/sysconfig/modules/ipvs.modules <<EOF
#!/bin/bash
modprobe -- ip_vs
modprobe -- ip_vs_rr
modprobe -- ip_vs_wrr
modprobe -- ip_vs_sh
modprobe -- nf_conntrack_ipv4
EOF
# 授权、运行、检查是否加载:
chmod 755 /etc/sysconfig/modules/ipvs.modules \
&& bash /etc/sysconfig/modules/ipvs.modules \
&& lsmod | grep -e ip_vs -e nf_conntrack_ipv4
检查是否加载:
lsmod | grep -e ipvs -e nf_conntrack
注意 nf_conntrack_ipv4 在现代 Ubuntu 中已经被移除,直接使用 nf_conntrack 就行了
重启三台 Linux 机器:
sudo reboot
安装 Docker
sudo apt-get install apt-transport-https ca-certificates curl gnupg-agent software-properties-common
# 添加 Docker 的官方 GPG 密钥:
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
# 通过搜索指纹的后8个字符,验证现在是否拥有带有指纹的密钥。
sudo apt-key fingerprint 0EBFCD88
# 设置稳定版仓库
sudo add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable"
sudo apt-get install docker-ce docker-ce-cli containerd.io
设置 Docker 镜像加速器:
sudo mkdir -p /etc/docker
# 更改地址
sudo tee /etc/docker/daemon.json <<-'EOF'
{
"exec-opts": ["native.cgroupdriver=systemd"],
"registry-mirrors": ["https://XXXXX.mirror.aliyuncs.com"],
"live-restore": true,
"log-driver":"json-file",
"log-opts": {"max-size":"500m", "max-file":"3"},
"storage-driver": "overlay2"
}
EOF
sudo systemctl daemon-reload
sudo systemctl restart docker
安装 kubeadm、kubelet 和 kubectl
由于 kubernetes 的镜像源在国外,非常慢,这里切换成国内的 阿里云镜像源:
sudo apt-get update \
&& sudo apt-get install -y apt-transport-https
curl https://mirrors.aliyun.com/kubernetes/apt/doc/apt-key.gpg | sudo apt-key add -
cat <<EOF >/etc/apt/sources.list.d/kubernetes.list
deb https://mirrors.aliyun.com/kubernetes/apt/ kubernetes-xenial main
EOF
sudo apt-get update
sudo apt-get install -y kubelet kubeadm kubectl
安装 kubeadm、kubelet 和 kubectl
- kubelet 是 kubernetes 工作节点上的一个代理组件,运行在每个节点上。
- kubeadm 用于快速搭建 Kubernetes 集群的工具
- kubectl 是控制台的客户端
sudo apt install kubelet kubeadm kubectl
kubelet --version
# 设置为开机自启动即可
systemctl enable kubelet
查看 k8s 状态
systemctl status kubelet
查看 k8s 所需镜像:
kubeadm config images list
# 预拉取镜像(可能要挂代理)
sudo kubeadm config images pull
部署 Master 节点
部署 k8s 的 Master 节点(192.168.150.100):
使用 kubeadm init 自动初始化一系列的组件
# 确保禁用了
sudo swapoff -a
free -m
# 由于默认拉取镜像地址k8s.gcr.io国内无法访问,这里需要指定阿里云镜像仓库地址
# 注意,这个下载时间有点久
# --ignore-preflight-errors=NumCPU 是在只有一个 CPU 的时候使用,例如 1G1M 的学生服务器。
sudo kubeadm init \
--apiserver-advertise-address=192.168.150.100 \
--image-repository registry.aliyuncs.com/google_containers \
--kubernetes-version v1.23.5 \
--service-cidr=10.96.0.0/12 \
--pod-network-cidr=10.244.0.0/16 \
--v=6
# 如果出错了,可以重置,它会清空启动的容器
sudo kubeadm reset
# 创建必要文件
rm -rf $HOME/.kube
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
命令执行完毕,当看到下面信息之后,说明集群主节点已经安装完毕了。
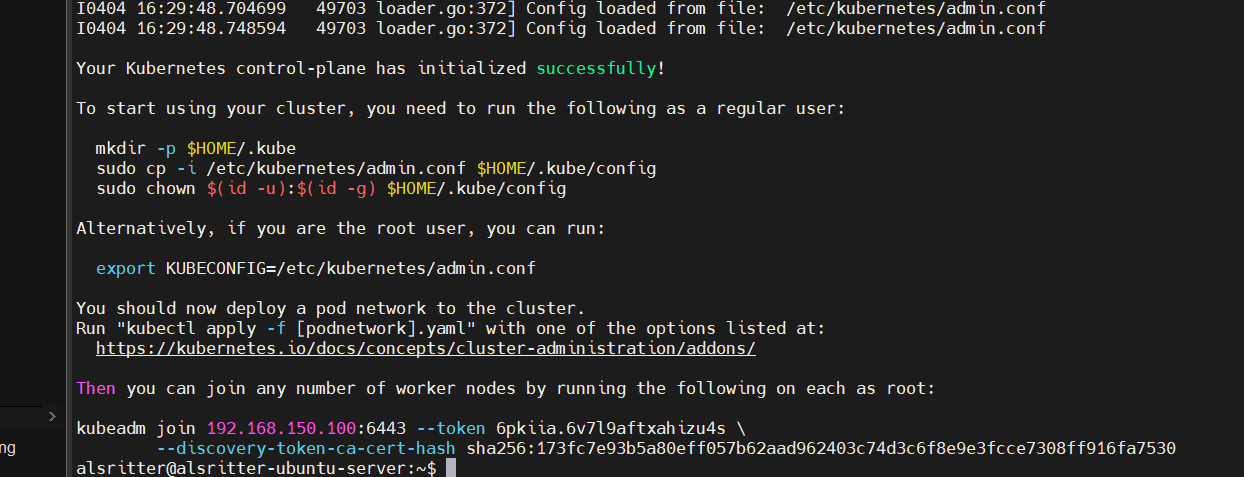
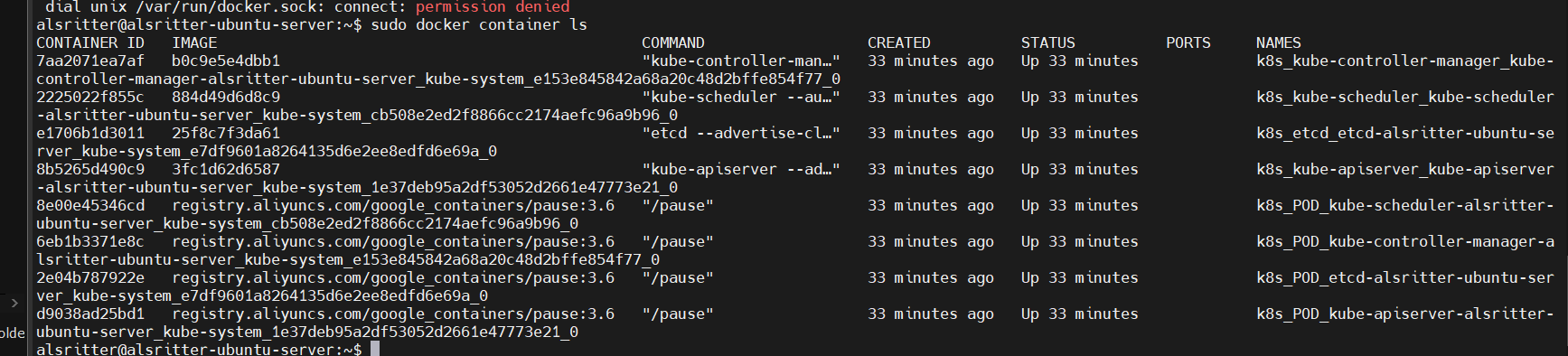
可以检查容器看到当前启动的容器
sudo docker container ls
部署 CNI 网络插件
根据提示,在 Master 节点上使用 kubectl 工具查看节点状态:
# 不要用 sudo
kubectl get pods --all-namespaces
可以看到各个 Node 节点都显示 NoReady,这是因为没有安装网络插件,各个节点是无法正常通信的
kubernetes支持多种网络插件,比如flannel、calico、canal等,任选一种即可,本次选择flannel,添加网络插件(需要挂代理)
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
如果不挂代理,也可以自己创建一个文件,执行本地的
vim kube-flannel.yml
kubectl apply -f $HOME/kube-flannel.yml
output:
odsecuritypolicy.policy/psp.flannel.unprivileged created
clusterrole.rbac.authorization.k8s.io/flannel created
clusterrolebinding.rbac.authorization.k8s.io/flannel created
serviceaccount/flannel created
configmap/kube-flannel-cfg created
daemonset.apps/kube-flannel-ds-amd64 created
daemonset.apps/kube-flannel-ds-arm64 created
daemonset.apps/kube-flannel-ds-arm created
daemonset.apps/kube-flannel-ds-ppc64le created
daemonset.apps/kube-flannel-ds-s390x created
查看部署 CNI 网络插件进度
kubectl get pods -n kube-system

再次在 Master 节点使用 kubectl 工具查看节点状态:
kubectl get nodes

可以看到这些网络节点已经可以正常通信了
部署 Node 节点
根据上面初始化最后的提示,在 192.168.150.101 和 192.168.150.102 上添加如下的命令,让它们加入集群:
sudo kubeadm join 192.168.150.100:6443 --token 9gsc4z.24zyk25qcyqjut3u --discovery-token-ca-cert-hash sha256:344df19b57f977c1c6394fc531ff082e9b64730f3432ca9e291053c567e361a8 --v=6
默认的 token 有效期为2小时,当过期之后,该 token 就不能用了,这时可以使用如下的命令创建 token:
kubeadm token create --print-join-command
# 生成一个永不过期的token
kubeadm token create --ttl 0 --print-join-command
# 检查全部 Pod
kubectl get pods --all-namespaces
配置 kubectl 命令自动补全
sudo apt install -y bash-completion
source /usr/share/bash-completion/bash_completion
# 应用 kubectl 的 completion 到系统环境:
source <(kubectl completion bash)
echo "source <(kubectl completion bash)" >> ~/.bashrc
ERROR: master 无法找到 Node
如果遇到 node 节点添加成功,master 节点看不到 node 信息,是因为 master 节点和 node 节点 hostname 相同,只显示一个,修改各自 hostname 名即可
一个主机名就是在网络上标记一个设备的标签名称。在同一个网络中,你不应该有两台或者更多机器拥有同样的主机名。
在 Ubuntu 中,你可以使用 hostnamectl 命令编辑系统主机名以及相关设置。这个工具识别三种不同的主机名:
static - 传统主机名。它存储在 /etc/hostname 文件中,并且可以被用户设置
pretty - 一个自由形态的 UTF8 主机名,用来代表用户。例如: Linuxize's desktop。
transient - 由 kernel 维护的动态主机名。 在运行过程中,DHCP 或者 mDNS 服务器可以改变 transient 主机名。默认情况下,它和 static 主机名一模一样。
显示当前主机名
hostnamectl
输出:
Static hostname: alsritter-ubuntu-node01
Transient hostname: alsritter-ubuntu-server
Icon name: computer-vm
Chassis: vm
Machine ID: 1f469763ee2040d6b52fea3f41cd5e83
Boot ID: 08a727d9076f43fbb3c930bf2fe6c3d7
Virtualization: vmware
Operating System: Ubuntu 20.04.4 LTS
Kernel: Linux 5.4.0-107-generic
Architecture: x86-64
修改系统主机名
sudo hostnamectl set-hostname node01
sudo hostnamectl set-hostname "node01" --pretty
sudo hostnamectl set-hostname node01 --static
sudo hostnamectl set-hostname node01 --transient
# 再检查一次
hostnamectl
在大多数系统中,主机名在 /etc/hosts 中被映射到 127.0.0.1。打开文件,并且修改旧的主机名到新的主机名。
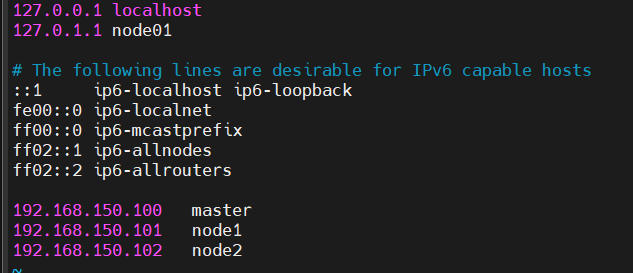
最后再初始化一次
sudo kubeadm reset
sudo kubeadm join 192.168.150.100:6443 --token z2mhcs.9gl2egin4t32mat0 --discovery-token-ca-cert-hash sha256:344df19b57f977c1c6394fc531ff082e9b64730f3432ca9e291053c567e361a8
最后就能在 Master 看到了
kubectl get nodes

ERROR: 无法连接 127.0.0.1:10248
错误处理:如何解决kubeadm init初始化时dial tcp 127.0.0.1:10248: connect: connection refused
这是 cgroup 驱动问题。默认情况下 Kubernetes cgroup 驱动程序设置为 system,但 docker 设置为 systemd。我们需要更改Docker cgroup驱动。
sudo vim /etc/docker/daemon.json
{
"exec-opts": ["native.cgroupdriver=systemd"]
}
systemctl daemon-reload
systemctl restart docker
systemctl restart kubelet
编辑 kubeadm-flags.env 的 cgroup 值 修改为 docker 一样的值
sudo vim /var/lib/kubelet/kubeadm-flags.env
# 修改
KUBELET_EXTRA_ARGS="--cgroup-driver=systemd"
KUBE_PROXY_MODE="ipvs"
# 然后重启一下
systemctl daemon-reload && systemctl restart kubelet
注意!!还有一种情况是没有关闭交换区
ERROR: 无法访问 localhost:8080
The connection to the server localhost:8080 was refused - did you specify the right host or port?
出现这个问题的原因是 kubectl 命令需要使用 kubernetes-admin 来运行,解决方法如下,将主节点中的 /etc/kubernetes/admin.conf 文件拷贝到从节点相同目录下,然后配置环境变量:
rm -rf $HOME/.kube
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
echo "export KUBECONFIG=$HOME/.kube/config" >> ~/.bash_profile
source ~/.bash_profile
ERROR: Pod 处于 Pending 状态
当 Pod 一直处于 Pending 状态时,说明该 Pod 还未被调度到某个节点上,需查看 Pod 分析问题原因。
kubectl get pod -n kube-system -o wide
kubectl describe pod <pod-name>